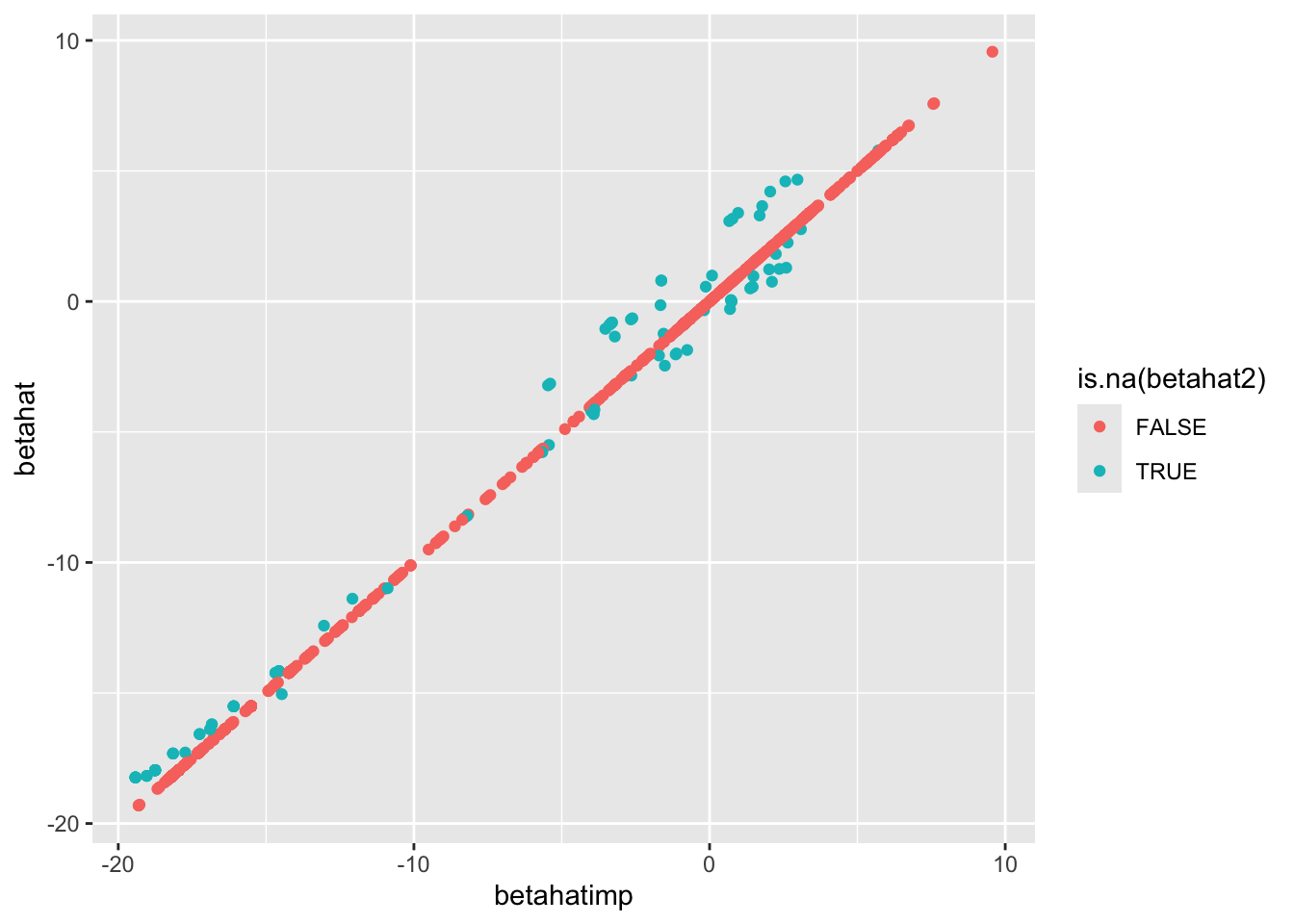
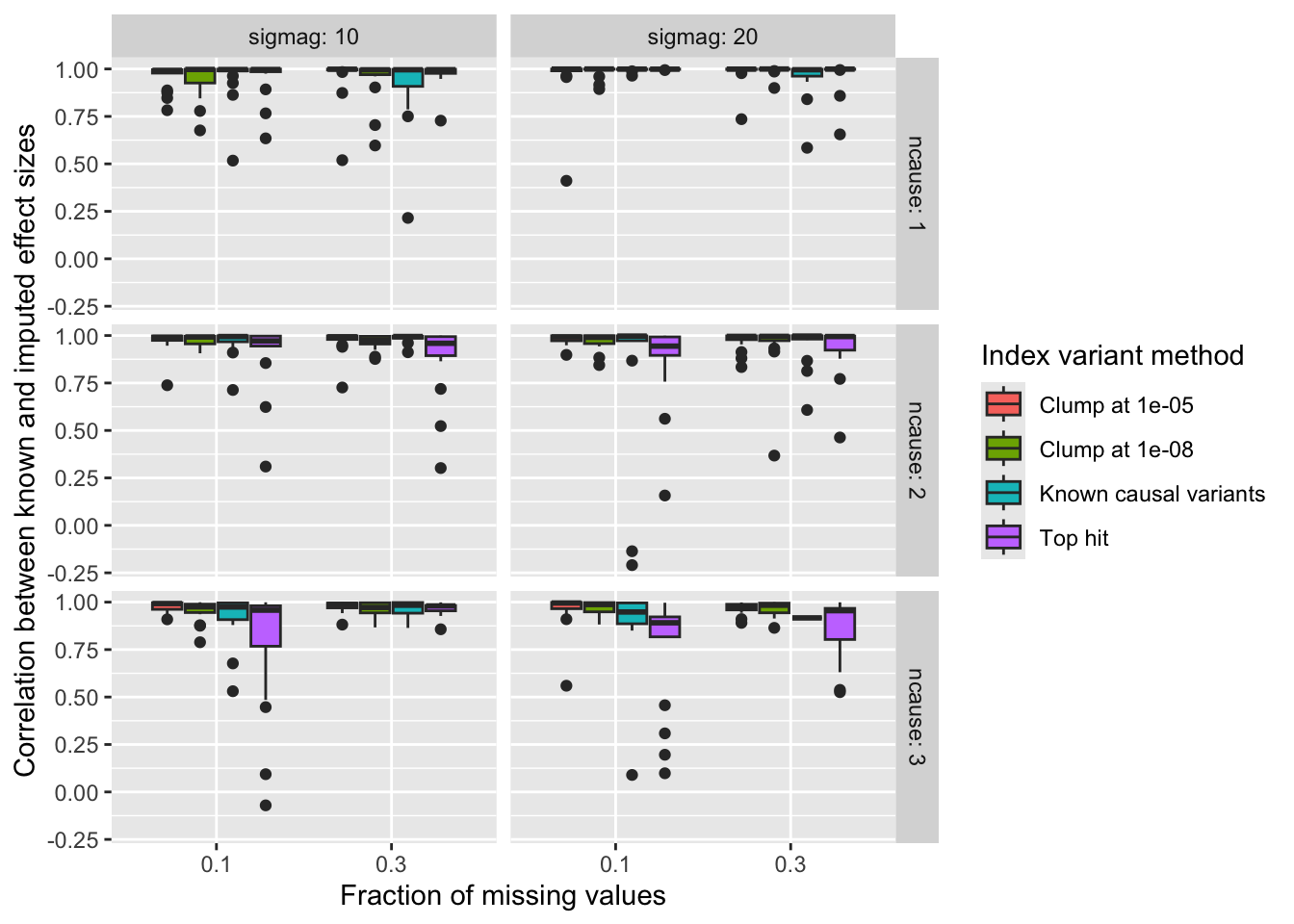
sim_all <- function(X, R, frac_missing, ncause, sigmag, zthresh, rthresh, seed=1234) {
ss <- simulate_ss(X, af, ncause, sigmag, seed)
ss <- generate_missing(ss, frac_missing)
if(zthresh == -1) {
index <- which(ss$b != 0)
} else if(zthresh == -2) {
index <- which.max(abs(ss$zhat))
} else {
index <- clump(ss$zhat2, R, qnorm(zthresh, low=FALSE), rthresh)
}
ss <- imp(R, ss, index)
return(ss)
}
params <- expand.grid(
frac_missing = c(0.1, 0.3),
ncause = c(1, 2, 3),
sigmag = c(10, 20),
zthresh = c(-1, -2, 1e-5, 1e-8),
rthresh = c(0.01),
sim = 1:20
)
dim(params)
res <- lapply(1:nrow(params), \(i) {
message(i)
p <- params[i,]
r <- tryCatch(sim_all(X, R, p$frac_missing, p$ncause, p$sigmag, p$zthresh, p$rthresh, seed=i), error=function(e) {return(NULL)})
tibble(
frac_missing = p$frac_missing,
ncause = p$ncause,
sigmag = p$sigmag,
zthresh = p$zthresh,
rthresh = p$rthresh,
sim = p$sim,
b_cor = r$b_cor,
se_cor = r$se_cor,
b_adj = r$b_adj,
se_adj = r$se_adj
)
}) %>% bind_rows()
save(res, file="simres.rdata")