Background
Identify GWAS catalog traits to import to OpenGWAS
Attaching package: 'dplyr'
The following objects are masked from 'package:stats':
filter, lag
The following objects are masked from 'package:base':
intersect, setdiff, setequal, union
library(tidyr)
library(data.table)
Attaching package: 'data.table'
The following objects are masked from 'package:dplyr':
between, first, last
API: public: http://gwas-api.mrcieu.ac.uk/
Get list of harmonised studies in GWAS catalog
download.file("ftp://ftp.ebi.ac.uk/pub/databases/gwas/summary_statistics/harmonised_list.txt", "harmonised_list.txt")
a <- scan("harmonised_list.txt", what=character())
head(a)
[1] "./GCST90086001-GCST90087000/GCST90086737/harmonised/35078996-GCST90086737-EFO_0007937.h.tsv.gz"
[2] "./GCST90086001-GCST90087000/GCST90086591/harmonised/35078996-GCST90086591-EFO_0007937.h.tsv.gz"
[3] "./GCST90086001-GCST90087000/GCST90086659/harmonised/35078996-GCST90086659-EFO_0007937.h.tsv.gz"
[4] "./GCST90086001-GCST90087000/GCST90086510/harmonised/35078996-GCST90086510-EFO_0007937.h.tsv.gz"
[5] "./GCST90086001-GCST90087000/GCST90086758/harmonised/35078996-GCST90086758-EFO_0007937.h.tsv.gz"
[6] "./GCST90086001-GCST90087000/GCST90086480/harmonised/35078996-GCST90086480-EFO_0007937.h.tsv.gz"
Get EBI IDs already in OpenGWAS
ao <- ieugwasr::gwasinfo()
gotebi <- grep("ebi-a", ao$id, value=TRUE) %>% gsub("ebi-a-", "", .)
Identify datasets not available
a <- tibble(path=a) %>%
tidyr::separate(path, sep="/", into=c("dot", "range", "id", "harmonised", "fn"), remove=FALSE) %>%
as_tibble %>%
tidyr::separate(fn, sep="-", into=c("pmid", "id2", "efo"), remove=FALSE) %>%
filter(!is.na(id2)) %>%
filter(!id %in% gotebi) %>%
dplyr::select(-c(id2, dot)) %>%
mutate(path=gsub("^./", "", path))
Warning: Expected 3 pieces. Missing pieces filled with `NA` in 4427 rows [4005, 4006,
4007, 4008, 4009, 4010, 4011, 4012, 4013, 4014, 4015, 4016, 4017, 4018, 4019,
4020, 4021, 4022, 4023, 4024, ...].
# A tibble: 22,932 × 7
path range id harmonised fn pmid efo
<chr> <chr> <chr> <chr> <chr> <chr> <chr>
1 GCST90086001-GCST90087000/GCST90086… GCST… GCST… harmonised 3507… 3507… EFO_…
2 GCST90086001-GCST90087000/GCST90086… GCST… GCST… harmonised 3507… 3507… EFO_…
3 GCST90086001-GCST90087000/GCST90086… GCST… GCST… harmonised 3507… 3507… EFO_…
4 GCST90086001-GCST90087000/GCST90086… GCST… GCST… harmonised 3507… 3507… EFO_…
5 GCST90086001-GCST90087000/GCST90086… GCST… GCST… harmonised 3507… 3507… EFO_…
6 GCST90086001-GCST90087000/GCST90086… GCST… GCST… harmonised 3507… 3507… EFO_…
7 GCST90086001-GCST90087000/GCST90086… GCST… GCST… harmonised 3507… 3507… EFO_…
8 GCST90086001-GCST90087000/GCST90086… GCST… GCST… harmonised 3507… 3507… EFO_…
9 GCST90086001-GCST90087000/GCST90086… GCST… GCST… harmonised 3507… 3507… EFO_…
10 GCST90086001-GCST90087000/GCST90086… GCST… GCST… harmonised 3507… 3507… EFO_…
# ℹ 22,922 more rows
There are 4427 that have no pmid, remove for now.
Summarise how many studies by pmid:
as <- a %>% group_by(pmid) %>% summarise(n=n()) %>% arrange(desc(n))
as %>% head(n=20)
# A tibble: 20 × 2
pmid n
<chr> <int>
1 34662886 7972
2 35078996 4753
3 34737426 2939
4 35668104 1863
5 33983923 1021
6 34503513 922
7 35115689 469
8 34594039 429
9 35115690 412
10 33437055 337
11 35213538 249
12 34017140 161
13 33414548 134
14 33959723 115
15 35264221 110
16 33328453 106
17 34226706 53
18 29892013 46
19 33623009 45
20 33283231 43
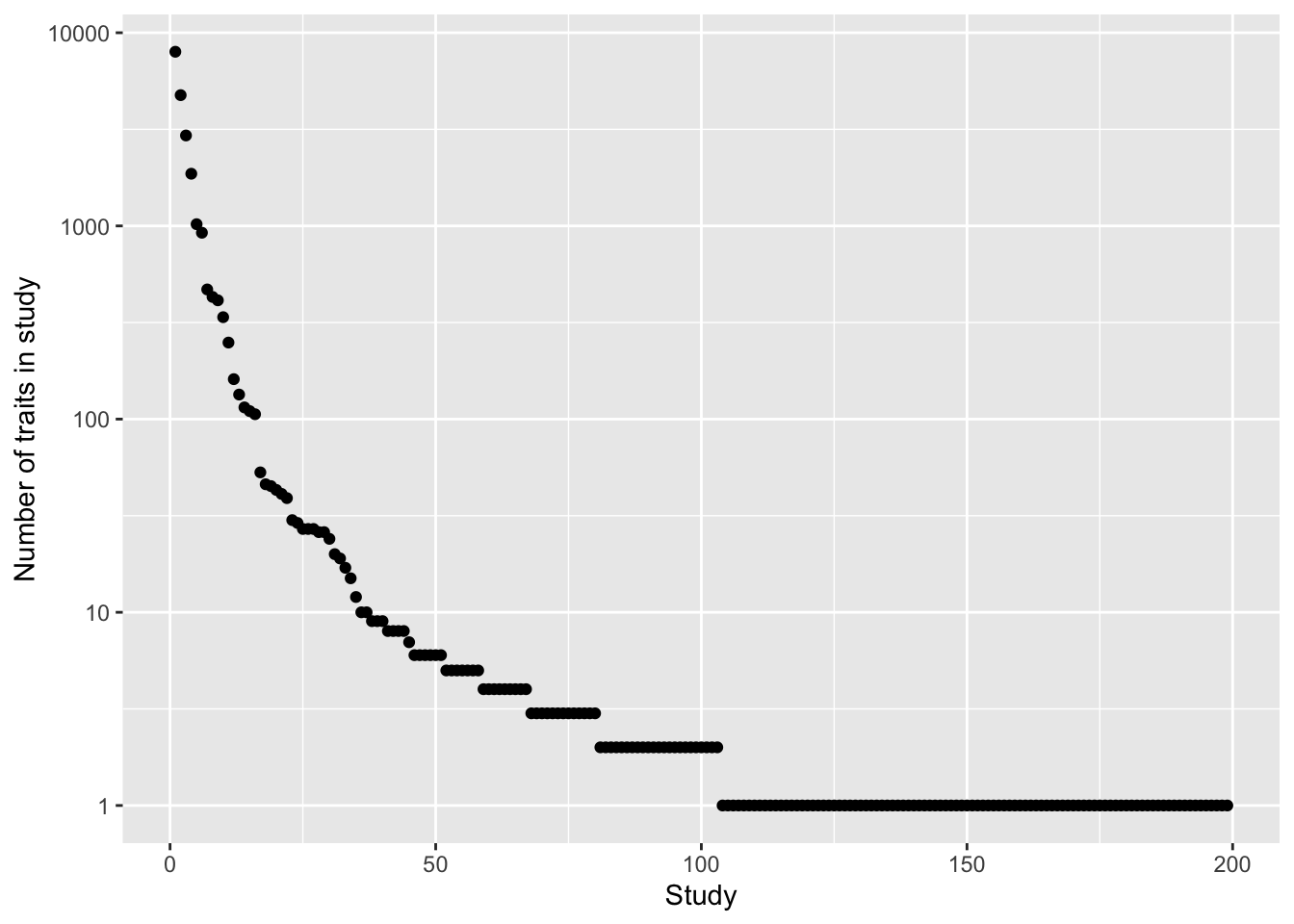
How many traits per study?
qplot(y=as$n, x=1:nrow(as)) +
scale_y_log10() +
labs(y="Number of traits in study", x="Study")
Warning: `qplot()` was deprecated in ggplot2 3.4.0.
How many traits to import if we only keep studies with fewer than 1000 traits
subset(as, n <= 1000) %>% {sum(.$n)}
How many traits to import if we only keep studies with fewer than 200 traits
subset(as, n <= 200) %>% {sum(.$n)}
Studies to ignore (for now at least)
pmid_ignore <- c(
34662886, # rare variant aggregate enrichment of ukb exome data
35078996, # pqtl
34737426, # ukb analysis (duplication of existing work)
35668104, # lipids superseded by others
33983923 # facial variation - 1k traits
)
a_keep <- subset(a, !pmid %in% pmid_ignore)
write.table(a_keep$path, file="gwascat_keeplist.txt", row=F, col=F, qu=F)
R version 4.3.0 (2023-04-21)
Platform: aarch64-apple-darwin20 (64-bit)
Running under: macOS Monterey 12.6.8
Matrix products: default
BLAS: /Library/Frameworks/R.framework/Versions/4.3-arm64/Resources/lib/libRblas.0.dylib
LAPACK: /Library/Frameworks/R.framework/Versions/4.3-arm64/Resources/lib/libRlapack.dylib; LAPACK version 3.11.0
locale:
[1] en_GB.UTF-8/en_GB.UTF-8/en_GB.UTF-8/C/en_GB.UTF-8/en_GB.UTF-8
time zone: Europe/London
tzcode source: internal
attached base packages:
[1] stats graphics grDevices utils datasets methods base
other attached packages:
[1] ggplot2_3.4.2 ieugwasr_0.1.5 data.table_1.14.8 tidyr_1.3.0
[5] dplyr_1.1.2
loaded via a namespace (and not attached):
[1] gtable_0.3.3 jsonlite_1.8.7 compiler_4.3.0 tidyselect_1.2.0
[5] scales_1.2.1 yaml_2.3.7 fastmap_1.1.1 R6_2.5.1
[9] labeling_0.4.2 generics_0.1.3 curl_5.0.2 knitr_1.43
[13] htmlwidgets_1.6.2 tibble_3.2.1 munsell_0.5.0 pillar_1.9.0
[17] rlang_1.1.1 utf8_1.2.3 xfun_0.39 cli_3.6.1
[21] withr_2.5.0 magrittr_2.0.3 digest_0.6.31 grid_4.3.0
[25] rstudioapi_0.14 lifecycle_1.0.3 vctrs_0.6.3 evaluate_0.21
[29] glue_1.6.2 farver_2.1.1 fansi_1.0.4 colorspace_2.1-0
[33] rmarkdown_2.22 purrr_1.0.2 httr_1.4.7 tools_4.3.0
[37] pkgconfig_2.0.3 htmltools_0.5.5