Probability of a random variable being larger than all other random variables in a multivariate normal vector
statistics
Author
Gibran Hemani
Published
November 1, 2022
I have 1k SNPs in a region. I know the causal variant and the LD matrix. The effect size at each SNP will be related to the allele frequency and the LD at all other variants. The SE across the SNPs will be correlated in relation to the LD. I can generate the expected effect size and the variance covariance matrix of the effects. Once I have that, I can generate beta values from a multivariate normal distribution, and determine how often each of the SNPs is the top SNP.
Is there a faster way to do this by getting the probability from a multivariate normal distribution?
Related to this question: https://stats.stackexchange.com/a/4181
library(MCMCpack)
Loading required package: coda
Loading required package: MASS
##
## Markov Chain Monte Carlo Package (MCMCpack)
## Copyright (C) 2003-2022 Andrew D. Martin, Kevin M. Quinn, and Jong Hee Park
##
## Support provided by the U.S. National Science Foundation
## (Grants SES-0350646 and SES-0350613)
##
library(dplyr)
Attaching package: 'dplyr'
The following object is masked from 'package:MASS':
select
The following objects are masked from 'package:stats':
filter, lag
The following objects are masked from 'package:base':
intersect, setdiff, setequal, union
library(simulateGP)library(MASS)library(mvtnorm)
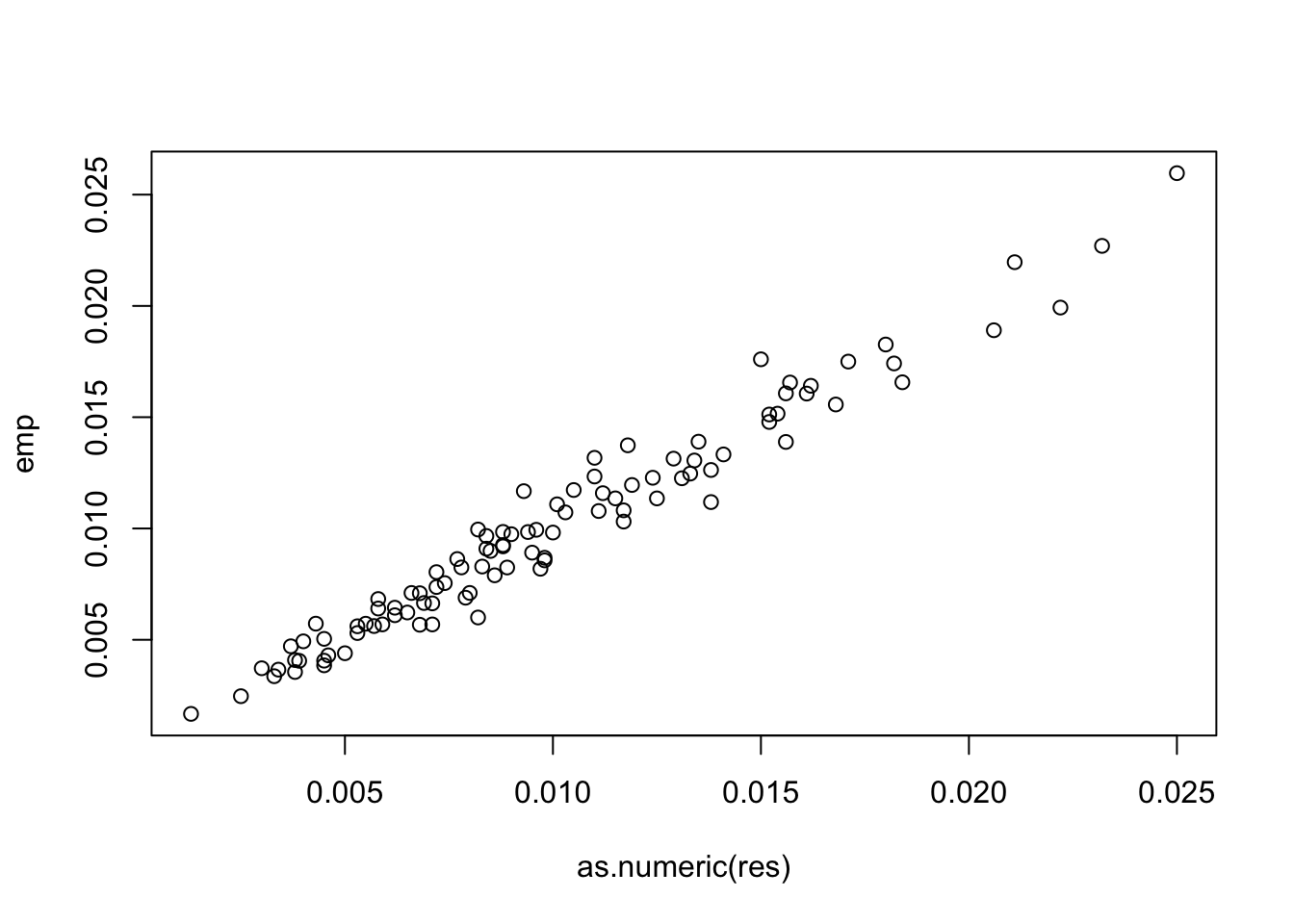
Empirical simulation for probabilities, case of 3 variables